
AI industry, obsessed with speed, is loathe to consider the energy cost in latest MLPerf benchmark | ZDNet
Qualcomm emphasized its top efficiency score on select AI tasks in the MLPerf benchmark test.
Qualcomm
One of the greatest challenges facing artificial intelligence is the vast amount of energy consumed by the computers that perform AI. Scholars of the discipline have for some time now sounded the alarm about the rising cost of energy given the ever-increasing size of AI programs, especially those of the deep learning variety, and the spiraling compute resources they consume.
As pointed out in a new five-year study, the AI100 report, published last week by Stanford University, “many within the field are becoming aware of the carbon footprint of building such large models,” referring to deep learning programs.
“There are significant environmental costs,” the study asserts.
Despite the pressing matter of sustainability, many of the leading vendors of chips and systems that run AI programs are more focused on achieving performance, in terms of raw speed, than they are watching out for energy efficiency.
The industry standard benchmark for machine learning computing performance, MLPerf, on Wednesday issued the latest vendor results for performance on benchmark tests of machine learning such as object recognition and natural language processing.
Compared to the previous report, in April, the number of submissions reporting on the energy cost of computing AI plummeted.
The new benchmark report, MLPerf Inference, version 1.1, received submissions from twenty vendors, totaling over 1,800 submissions. Of those, just 350 submissions reported measurements of power consumed.
That compares to 17 organizations and 1,994 submissions in April that included 864 power measurements. Hence, the proportion of submissions including power measurement dropped by more than half from the prior report to the latest.
“The numbers don’t lie, it’s a lot less power results this time than it was before,” David Kanter, the executive director of MLCommons, the industry consortium that oversees MLPerf, told ZDNet when asked about the sharp drop in energy measurements.
Also: Ethics of AI: Benefits and risks of artificial intelligence
The benchmark results were disclosed Wednesday in a press release by MLCommons, with a link to details of the submissions by vendors listed in multiple accompanying spreadsheets.
The drop in power measurement is directly tied to vendors’ quest to emphasize performance, first and foremost, to claim bragging rights, while placing energy consumption in second place as a concern.
Energy consumed and performance in terms of speed are typically trade-offs: any optimization of one detracts from the other. A chip’s voltage is typically boosted to goose performance in clock frequency, but a boost in voltage typically leads to a squared increase in power consumption.
“Your best performance efficiency will be at P-min, your best performance will be at P-max,” said Kanter, referring to minimum and maximum power thresholds.
At the same time, the task of reporting results to MLPerf is like taking an exam, and Nvidia and other vendors are deciding where to place their effort.
Also: AI industry’s performance benchmark, MLPerf, for the first time also measures the energy that machine learning consumes
“Inference runs take a certain amount of time, the minimum is ten minutes,” said Kanter of the programmed tests needed to gather data for submissions. Adding extra factors such as measuring power and not just speed adds overhead. “It does come down to resources,” he said.
MLPerf Inference 1.1 is only the second time the benchmark has included power measurements, which were introduced with the April report. The benchmark evaluates computer performance on the two main parts of machine learning, so-called training, where a neural network is built by having its settings refined in multiple experiments; and so-called inference, where the finished neural network makes predictions as it receives new data.
The inference function consumes far more power than the training side, said Kanter, given that inference is constantly serving requests for predictions, while training is a less frequent activity that takes place offline in the development of programs.
“If you look at how ML is used, the dominant power consumption is on the inference side,” said Kanter. That is especially important in the case of battery-powered devices that perform inference. The MLCommons introduced a separate benchmark for performance and power for such devices this year.
Among the 20 organizations submitting this year, Nvidia, whose graphics processing units dominate AI computing, took top honors in the majority of categories. Out of a total of 46 submissions by Nvidia published in the final results, only five were accompanied by power measurements.
That means that 11% of Nvidia’s published submissions were with power measurements, half the overall average of published submissions across vendors of 22%. Multiple vendors made submissions using Nvidia technology, including Dell, some of which included power measurements.
The trade-off of performance versus power comes down to how vendors will spend their engineers’ limited resources, something that is an issue even for a company such as Nvidia with a vast army of engineers.
“You’re working your engineers 24/7” to get test results compiled for submission to MLPerf, Dave Salvator, Nvidia’s senior product manager for AI and cloud, told ZDNet.
“Measuring performance is one set of challenges, and you’re dealing with how much time do we have to measure both performance and power,” he said. “In a lot of instances, we decided to keep our emphasis more on the performance side of things rather than power.”
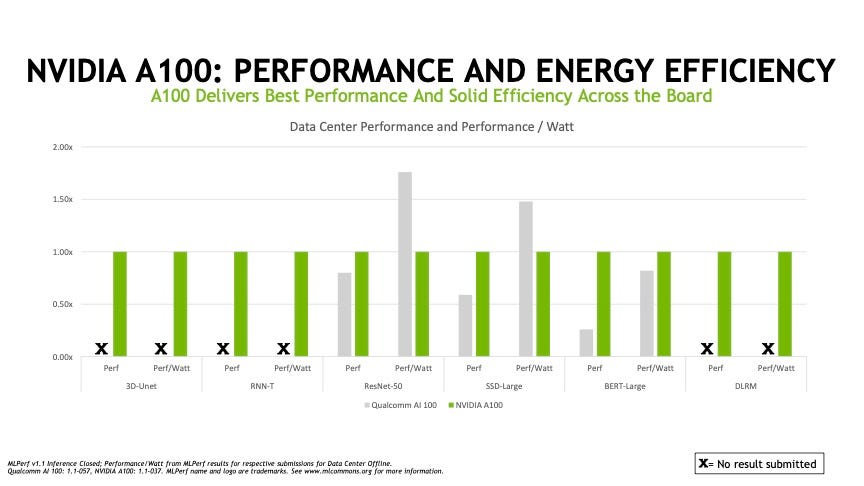
Nvidia says it has struck the right balance in emphasizing performance and also showing efficiency across a broad swathe of AI tasks.
Nvidia
Salvator noted Nvidia’s results showed the company putting “our best foot forward” in terms of delivering leading performance and also having greater performance per watt, known as efficiency of compute, in the most number of instances. “We’re showing leading performance, across the board, as well as efficiency in what we think covers the great swathe of usages.”
Asked whether MLPerf could do anything to reduce the trade-offs that make power reporting fall by the wayside, Salvator replied, “It’s a good question; we are always looking for ways to make interesting submissions, not just quantity but quality as well.”
Added Salvatore, Nvidia has “new products coming that will be pretty interesting in the efficiency side of things, and you’ll probably see us with power submissions on that.”
Mobile chip vendor Qualcomm, which has made a push to challenge Nvidia in edge devices that perform inference, reported a far greater proportion of submissions with power measurements, 8 of 18, or 44%, four times the proportion of Nvidia’s submissions.
Although Qualcomm fell far short of Nvidia in the number of top-scoring performance results, it had some notable wins in power efficiency. A Qualcomm system containing 16 of its “Cloud AI 100” accelerator chips delivered a third better speed on the venerable Resnet-50 neural network test of recognizing images compared to an 8-chip Nvidia A100 system, despite consuming 25% less energy.
The achievement lead Qualcomm to trumpet its chips as having “the most efficient AI inference solution.”
Qualcomm’s lead executive for its MLPerf effort, John Kehrli, senior director, product management, remarked of the power measurement, “we are very excited that this forum takes that into account, we think that matters, and we continue to focus on that.”
Asked if the power measurement has been rendered obsolete by too few submissions, MLPerf’s Kanter replied, “If we really don’t get any power submission, then what we’re doing is not adding value.” That may imply a re-think is needed as to how power is being measured, he suggested.
At the same time, said Kanter, there is a matter of “quality over quantity.”
“Ultimately, MLPerf is about helping guide the industry to align, to help customers understand what to do, to help designers understand what to do,” said Kanter. “As long as we’re serving that function, it’s important.”
For all the latest Technology News Click Here
For the latest news and updates, follow us on Google News.