

Researchers at Tianjin University of Technology in China have recently developed a new brain network-based framework for recognizing the emotions of deaf individuals. This framework, presented in a paper published in IEEE Sensors Journal, is specifically based on a computational technique known as stacking ensemble learning, which combines the predictions made by multiple different machine learning algorithms.
“In daily communication with deaf students, we found that they recognize the emotions of other people were mainly based on visual observation,” Yu Song, one of the researchers who carried out the study, told Tech Xplore. “Compared with normal people, there are also certain differences in the perception of emotions by deaf, which may cause some problems such as psychological deviations in daily life.”
Most past studies aimed at developing emotion recognition models were carried out on individuals with no sensory impairments. Song and his colleagues set out to fill this gap in the literature, by developing a framework that can specifically classify the emotions of deaf individuals.
First, the researchers examined the differences in brain activity and functional connectivity between subjects with no hearing impairments and deaf individuals when in three different emotional states (positive, neutral and negative). To do this, they recruited 15 deaf students at Tianjin University of Technology and collected similar brain recordings as those in the SEED dataset, a renowned dataset containing several EEG signals of subjects with no hearing impairments.
“Typically, EEG features are extracted from the time domain, frequency domain, and time-frequency domain for emotion recognition,” Song explained. “This is because neuroscience theory suggests that cognitive processes are reflected by the propagation of information in the brain and interactions between different brain regions. We hence decided to develop a novel brain network stacking ensemble learning model for emotion recognition that combines the information gathered by different algorithms.”
In their initial experiment, Song and his colleagues found that the selection of the threshold value played an important role in their construction of the brain network. To reduce false connections and retain valid ones, they thus proposed to use thresholds that were double to binary in the phase-locking value (PLV) connection matrix. The PLV is a measure of the phase synchrony between two different time series that is widely used to examine brain connectivity through the analysis of imaging data, such as MEG and EEG scans.
“We then extracted the global features and local features from the brain network and used the stacking ensemble learning framework we developed to classify the extracted features,” Song said. “Our experimental results show that the proposed model can learn discriminative and domain-robust EEG features for improving the accuracy of emotion recognition. Differently from deep learning, our model is also suitable for small sample data and can effectively reduce the risk of overfitting.”
In their experiments, Song and his colleagues found that their model could recognize the emotions of deaf individuals with significantly greater accuracy than it recognized the emotions of people with no hearing impairments. A possible explanation for this is that deaf individuals have a simpler understanding of emotions due to their lack of one channel associated with emotion acquisition.

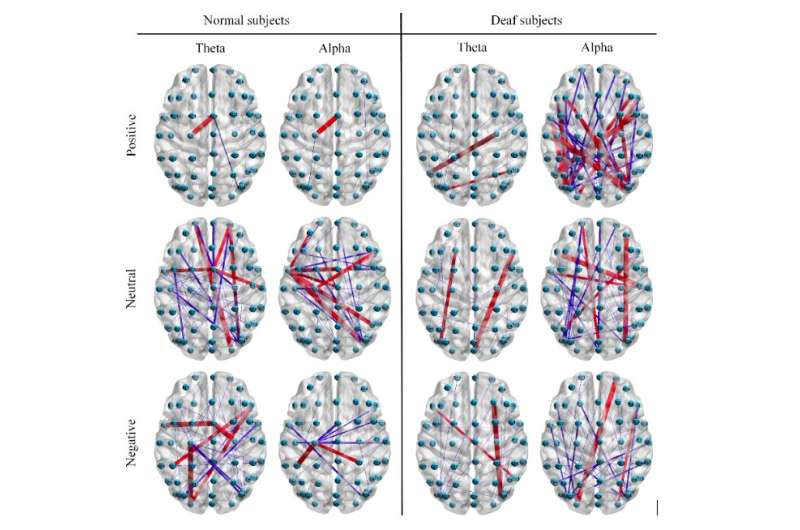
Remarkably, the researchers’ model significantly outperformed other state-of-the-art models for emotion recognition. In addition, the team found that the differences in brain activity and functional connectivity between deaf and non-hearing-impaired subjects were more obvious in emotionally charged states than in neutral conditions.
“For normal subjects, we found that the left prefrontal and temporal lobes are probably the most abundant emotion information area by investigating brain activity,” Song said. “For deaf subjects, the frontal, temporal and occipital lobes are probably the most abundant emotion recognition information area.”
The study provided valuable insight about the differences between the brain activity of deaf and hearing individuals in different emotional states. For instance, Song and his colleagues observed that compared to hearing subjects, deaf subjects exhibit higher activation in the occipital and parietal lobes, and lower activation in the temporal lobe. These differences could be related to the compensation mechanism in the brain of deaf participants as they watched the emotional movie clips showed to them during the experiment.
“We found that for normal subjects, the local inter-channel relations among frontal lobes may provide useful information for emotion recognition, and the global inter-channel relations between frontal, parietal, and occipital lobes may also provide useful information,” Song said. “For deaf subjects, on the other hand, the global inter-channel relations among frontal, temporal, and occipital lobes are of great significance for emotion recognition, as well as inter-channel relations between right and left hemispheres of the brain may also provide useful information.”
The study could have several important implications. First, the work could improve the current understanding of how emotional states are manifested in the brains of deaf individuals and how this differs from emotional processing in people with no hearing impairments.
In addition, the emotion recognition model they developed could be used to identify the emotions of deaf people both in everyday and clinical settings. In addition, the researchers’ work could inform the development of strategies to reduce differences in emotional cognition between deaf and hearing individuals.
The model can currently achieve an accuracy of approximately 60% across subjects when applied to the 15 deaf participants they recruited. In the future, Song and his colleagues hope to improve their model’s performance and its ability to generalize well across different individuals.
“Recently, we have also begun to recruit more deaf subjects to participate in the experiment of EEG emotion recognition, and categories of emotions include amusement, encouragement, calmness, sadness, anger and fear,” Song added. “We will continue to expand our dataset and provide it freely to the world researchers in later work so that they can study the brain nerve mechanism of deaf subjects under different emotional states.”
Emotion recognition from deaf EEG signals using stacking ensemble learning framework based on a novel brain network. IEEE Sensors Journal (2021). DOI: 10.1109/JSEN.2021.3108471
© 2021 Science X Network
Citation:
New model recognizes emotions in deaf individuals by analyzing EEG signals (2021, September 28)
retrieved 28 September 2021
from https://techxplore.com/news/2021-09-emotions-deaf-individuals-eeg.html
This document is subject to copyright. Apart from any fair dealing for the purpose of private study or research, no
part may be reproduced without the written permission. The content is provided for information purposes only.
For all the latest Technology News Click Here
For the latest news and updates, follow us on Google News.